一、存储引擎
1. InnoDB
InnoDB 存储引擎支持事务,其设计目标主要面向在线事务处理(OLTP)的应用。其特点是行锁设计、支持外键,并支持类似于 Oracle 的非锁定读,即默认读取操作不会产生锁。从 MySQL 数据库 5.5.8 版本开始 InnoDB 存储引擎是默认的存储引擎。
InnoDB 存储引擎将数据放在一个逻辑的表空间中,这个表空间就像黑盒一样由 InnoDB 存储引擎自身进行管理。从 MySQL4.1(包括4.1) 版本开始,它可以将每个 InnoDB 存储引擎的表单独存放到一个独立的 ibd 文件中。此外 InnoDB 存储引擎支持 用裸设备(row disk)用来建立其表空间。
InnoDB 通过使用多版本并发控制(MVCC)来获得高并发性,并且实现了 SQL 标准的 4 种隔离级别,默认为 REPEATABLE 级别。同时,使用一种被称为 next-key locking 的策略来避免幻读(phantom)现象的产生。除此之外,InnoDB 储存引擎还提供了插入缓冲(insert buffer)、二次写(double write)、自适应哈希索引(adaptive hash index)、预读(read ahead)等高性能和高可用的功能。
对于表中数据的存储,InnoDB 存储引擎采用了聚集(clustered)的方式,因此每张表的存储都是按主键的顺序进行存放。如果没有显式地在表定义时指定主键,InnoDB 存储引擎会为每一行生成一个 6 字节的 ROWID,并以此作为主键。
2. MyISAM
MyISAM 存储引擎不支持事务、表锁设计,支持全文索引,主要面向一些 OLAP 数据库应用。在 MySQL5.5.8 版本之前 MyISAM 存储引擎是默认的存储引擎(除 Windows 版本外)。
数据库系统与文件系统很大的一个不同之处在于对事务的支持,然而 MyISAM 存储引擎是不支持事务的。究其根本,这也不是很难理解。试想用户是否在所有的应用中都需要事务呢?在数据仓库中,如果没有 ETL 这些操作,只是简单的报表查询是否还需要事务的支持呢?此外 MyISAM 存储引擎的另一个与众不同的地方是它的缓冲池只缓存(cache)索引文件,而不缓冲数据文件,这点和大多数的数据库都非常不同。
MyISAM 存储引擎表由 MYD 和 MYI 组成,其中 MYD 用来存放数据文件,· 用来存放索引文件。可以通过使用 myisampack 工具来进一步压缩数据文件,因为 myisampack 工具使用赫夫曼(Huffman)编码静态算法来压缩数据,因此使用 myisampack 工具压缩后的表是只读的,当然用户也可以通过 myisampack 来解压数据文件。
二、表的结构
从 InnoDB 存储引擎的逻辑存储结构看,所有数据都被逻辑地存放在一个空间中,称之为表空间(tablespace)。
表空间又由段(segment)、区(extent)、页(page)组成。页在一些文档中有时也称为块(block),存储结构大致如图所示。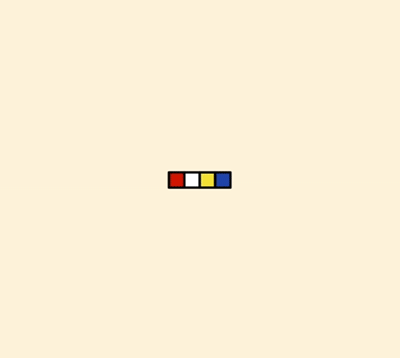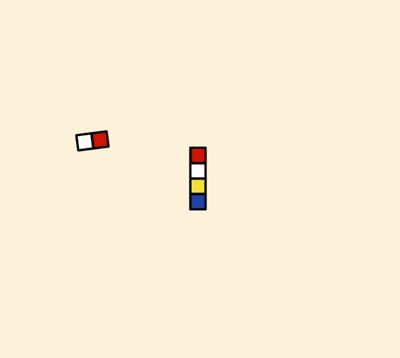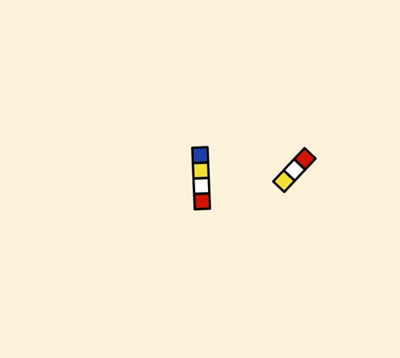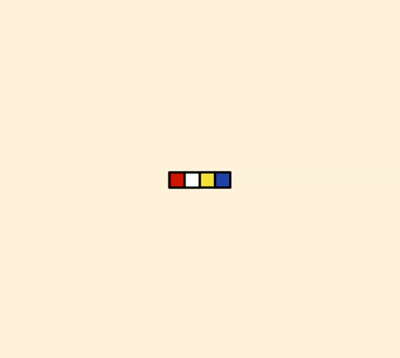
1. 段(Segment)
表空间是由各个段组成的,常见的段有数据段、索引段、回滚段等。
InnoDB 存储引擎表是索引组织的(index organized),因此数据即索引,索引即数据。那么数据段即为 B+ 树的叶子节点,索引段即为 B+ 树的非索引节点。
在 InnoDB 存储引擎中,对段的管理都是由引擎自身所完成,DBA 不能也没有必要对其进行控制,和 Oracle 数据库中的自动段空间管理( ASSM )类似,从一定程度上简化了 DBA 对于段的管理。
2. 区(extent)
区是由连续页组成的空间,在任何情况下每个区的大小都为 1MB,为了保证区中页的连续性,InnoDB 存储引擎一次从磁盘申请 4~5 个区。
在默认情况下,InnoDB 存储引擎页的大小为 16KB,即一个区中一共有 64 个连续的页。InnoDB 1.Ox 版本引入压缩页,即每个页的大小可通过参数 KEY SIZE 调整为 2K、4K、8K,因此每个区对应页的数量就应该为 512、256、128,但不论页的大小怎么变化,区的大小总是为 1M。
3. 页(page)
InnoDB 同大多数数据库一样有页(Page)的概念(也可以称为块),页是 InnoDB 磁盘管理的最小单位,默认每个页的大小为 16KB。
从 InnoDB 1.2.x 版本开始,可以通过参数 innodb_page_size 将页的大小设置为 4K、8K、l6K,设置后表中索引页的大小都为 innodb_page_size 所指定的大小且不允许二次修改,除非通过 mysqldump 导人和导出操作来产生新的库。
一个 16k 大小的页并不是全部空间都用于存放记录数据,其被拆分为三部分,其中页头用于存放页号与页的指针等信息,只有数据区才是真正用于存放的数据的部分,其结构示意图如下:
4. 行(row)
Compact 行记录是在 MySQL 5.0 中引入的,其设计目标是高效地存储数据。简单来说,一个页中存放的行数据越多,其性能就越高,其存储结构示意图如下。
(Ⅰ) 变长字段长度列表
- 按照列的顺序逆序放置的。
- 若列的长度小于
255字节,用1字节表示,若大于255个字节,用2字节表示。 - 最大不可以超过
2字节,因为MySQL中VARCHAR类型的最大长度限制为65535。
(Ⅱ) NULL 标志位
- 该部分所占的字节应该为
1字节。 - 标识该行数据中是否有
NULL值,有则用1表示。
(Ⅲ) 记录头信息(record header)
- 固定占用
5字节(40位),含义见下表。
需要特别注意的是,NULL 不占该部分任何空间,即 NULL 除了占有 NULL 标志位,实际存储不占有任何空间。另外每行数据中除了用户定义的列外,还有两个隐藏列,事务 ID 列和回滚指针列,分别为 6 字节和 7 字节的大小。此外若 InnoDB 表没有定义主键,每行还会增加一个 6 字节的 rowid 列。
5. 存储结构
在 MySQL 中数据是依据 B+ 树结构进行存在,即非叶子节点仅用于索引作用,真实行数据记录都存于叶子节点中,其结构示例图如下:
三、日志文件
1. Redo log
Redo Log 是一种记录 MySQL 数据更改机制,记录了物理层面上数据页的变化情况,当系统发生崩溃或意外宕机时,会读取 redo log 文件内的内容实现数据恢复。
(1) 日志组
Redo log 并不是以单个文件形式存在,而是由多个文件组成的一个 group,存在下述两个参数配置:
innodb_log_files_size: 指定组内的单个文件的大小。innodb_log_files_in_group: 指定组内的文件数据量。
如默认的 group 由两个文件 ib_logfile0 与 ib_logfile1 组成,当数据变更发生时,会先将执行操作信息(数据页的更改)追加至 group 内文件的末端,若该文件已满则会切换 (async checkpoint) 至组内的其他文件并将数据追加到其末端。
(2) buffer pool
Redo Log 分为两个部分:内存缓冲区(buffer pool) 和 磁盘文件(log file)。内存缓冲区是用来提高性能的,当写入 redo log 时会先写入 redo log buffer 中,再按照一定机制转写入 redo log file 中。
即通过 redo log 记录一份操作日志备份,当在数据更新内存未及时刷新回磁盘时宕机,即可通过 redo log 读取丢失数据。
redo log buffer转写通过innodb_flush_log_at_trx_commit参数配置。
- 1:实时将变更刷入服务器磁盘中,稳定性最高效率最低。
- 0:将变更刷入
Redo log buffer,再定期将Redo log buffer数据写入磁盘。- 2:将变更刷入物理机内存中,再每隔一秒执行一次数据磁盘写入操作,更推荐此方案。
2. Undo log
Undo log 用于处理事务数据回滚,将修改前数据存入 Undo log ,此时若发生事务即可直接从 Undo log 中读取变化前数据实现事务数据回滚。
3. Bin log
Bin log 是 MySQL 的一种服务器日志,用于记录 SQL 层面的数据更新操作,包括数据定义语句 (DDL) 和数据操作语句 (DML) 等。
与 Redo log 不同,Bin log 是在 MySQL Server 层产生的,记录的是 SQL 语句或者语句的逻辑,而不是物理的数据变更操作。Bin log 可以用于数据恢复、数据复制和数据同步等操作,也可以用于查询和数据分析等工作,例如常见的 CDC 即利用 bin log 机制实现。
(1) Log level
bin log 记录的数据存在三种类型,通过参数 binlog_format 控制,其可选值如下:
ROW
在ROW级别下即记录的是具体的变更数据,如通过update更新了5条数据,则记录下这五条真实数据内容。即详细记录下每一条数据的变更内容,但缺点也很明显就存储资源占用更高。STATEMENT
在STATEMENT级别下记录的是对应的执行语句,同样为通过update更新了5条数据,此时bin log记录存储下的则为update语句而非具体的数据记录。因此,
STATEMENT模式不像ROW可获取变更前的数据,只可通过sql查询到变更后的最新数据。MIXWD
在MIXWD混合模式下由MySQL动态决策当前变更采用ROW或STATEMENT方式。混合模式下监听到数据格式将不再统一,可能是具体数据也可能是
SQL,解析复杂度更高对消费方并不友好,如非必要并不推荐此模式。
四、存储机制
1. 读写机制
在 MySQL 中数据存储包含 内存 与 磁盘 两个部分,增删改操作首先会被写入到 redo log 中,保证数据的持久性。同时为了提高写入性能,MySQL 还引入了 Change Buffer 机制,将写入的数据先暂存在 Change Buffer 中,再由后台线程定时将其刷入磁盘。
在执行查询操作时,先从 Change Buffer 中读取数据,如果数据已经被修改,会将修改后的数据写回磁盘,然后再返回给查询请求。如果数据没有被修改,则直接返回内存中的数据。这样可以避免频繁地从磁盘读取数据,提高查询性能。
Change Buffer的执行顺序如下:
- 增删改操作时,记录
redo log,同时将数据写入Change Buffer。- 后台线程定时将
Change Buffer中的数据刷入磁盘。- 当
MySQL崩溃后,重启时会先检查redo log,将未持久化的数据写入磁盘,然后再将Change Buffer中的数据刷入磁盘。
2. Change Buffer
Change Buffer(变更缓存) 是一种缓存机制,它会将某些更新操作缓存在内存中,而不是直接写入磁盘,这样可以减少磁盘随机写入,提高性能。
当查询需要用到已经缓存在 Change Buffer 中的记录时,MySQL 会将缓存中的数据写入磁盘并清空缓存。如果缓存中的数据过多或占用内存过大, MySQL 会将缓存中的数据写入磁盘并清空缓存,以保证内存的可用性。
InnoDB 的 Change Buffer 包含了多种 DML 操作,如增删改对应 Insert Buffer、Delete Buffer 和 Purge Buffer,其运行流程大致如下:
Change Buffer中的操作应用到原数据页,得到最新结果的过程称为merge。
- 访问这个数据页会触发
merge。- 系统有后台线程会定期
merge。- 在数据库正常关闭
(shutdown)的过程中,也会执行merge操作
(1) 区别差异
Change Buffer 和 Redo Log 都是 MySQL 提高性能和保证数据一致性的重要机制,它们的作用是互相补充的。
Change Buffer用来提高更新操作的性能,而Redo Log则用来保证数据的一致性和可恢复性。Bin log记录的是Server层逻辑变更,而Redo Log记录的是物理层数据变更。
3. 二阶段提交
在上面介绍了 MySQL 数据的操作流程,变更的数据会先写入 Change Buffer 中再有执行器定期写入 Redo log,若通过 SQL 等操作变更则会同时触发 Bin log 机制,其基本的执行流程如下所示。
下图中以数据插入为例,若为更新等操作在 Change Buffer 与 Redo log 之间通常存在 Undo log 操作用于数据的事务回滚。
但上述的存在一种特殊情况,即 Redo log 写入是正常但由于某些原因使得 Bin log 没有正常更新,也就导致了 Redo log 与 Bin log 二者数据出现不一致的情况。
为此 MySQL 中引入了二阶段提交操作,将 Redo log 操作拆分为准备(prepare)与提交(commit),若 Bin log 出现异常则 Redo log 状态将停止于 prepare,当通过 Redo log 恢复数据时读取状态为 prepare 将通过事务回滚读取 Bin log 的值,即发生变更之前的数据,从而保证了数据的一致性。
参考文档
- 《MySQL InnoDB存储》
- 为什么大家说mysql数据库单表最大两千万?依据是啥?